Accessing Results¶
palaestrAI does not only provide a way to setup experiments, it also automagically stores all results: Everything that is passed between agents and environments, such as sensor readings, setpoints, rewards, etc.; also, all static configuration data up to the actual experiment (run) documents can be found in the results database. The results database is called the “store” for short.
Configuration¶
Access to the store is configured by setting the respective key in the
runtime configuration. By default, it is set to
store_uri: sqlite:///palaestrai.db, i.e., palaestrAI will try to use
a local SQLite database. See the section on
runtime configuration for more details.
palaestrAI does not automatically create tables for you, but can do so if
instructed. Just run palaestrai database-create or use
palaestrai.store.setup_database(), e.g., when running a
Jupyter Notebook.
Connection¶
Once your database is configured, establishing a connection is as easy as:
from palaestrai.store import Session
dbh = Session()
- palaestrai.store.Session() Session[source]¶
Creates a new, connected database session to run queries on.
This is a convenience function that creates and returns a new, opened database session. It uses the access data provided by ::RuntimeConfig.store_uri. It exists in order to facilitate working with the store, such as this:
from palaestrai.store import Session, database_model as dbm session = Session() q = session.query(dbm.Experiment)
Returns:¶
- sqlalchemy.orm.Session
The initialized, opened database session.
Query API¶
palaestrAI’s database backend offers a simple (but growing) API for querying. It is accessible from the ::palaestrai.store.query module. The module integrates with the runtime configuration, i.e., the global database credentials configuration is also used here. The query API is convienient as it returns pandas or dask dataframes, which can then be easily used in Jupyter notebooks or for plotting.
Store Query API.
palaestrAI provides a hierarchical database schema where experiments, experiment runs, agent/environment configurations, as well as states, actions, and rewards are stored. The ::palaestrai.store.query module provides convenience methods for the data that is requested most of the time, such as experiment configuration or agent rewards. All data is returned either as pandas DataFrame or dask DataFrame, depending on the expected size of the data and query options.
All query functions offer some parameters to filte the query.
The easiest option is to pass a data frame via the like_dataframe
parameter. This constructs the query according to the contents of the data
frame:
The column names are the table’s attributes and all data frame contents are
used as filter predicate in to construct a query using the schema of
WHERE column_name IN [cell1, cell2, cell3] AND column_name_2 IN ....
More colloquially, this means that the data frame passed via the
like_dataframe parameter contains the data used for filtering.
If a data frame contains the columns experiment_run_uid and
agent_name, and the contents are 1, 2, and a1 and a2,
respectively, then the results from the database contain only those rows where
the experiment run UID is either 1 or 2, and the agent name is
either a1 or a2.
In addition, each query function also has explicitly spelled out parameters
for filtering.
E.g., with experiment_run_uids, only the mentioned experiment run UIDs
are being queried.
If multiple parameters are specified, they are joined with an implicit
logical and.
E.g., if both experiment_run_uids and experiment_run_phase_uids are
specified, then the database is queried for data that belongs to the
specified experiment runs AND the specified experiment run phases.
The resulting query that is rendered is equivalent to
... experiment_run.uid IN ... AND experiment_run_phase.uid IN ....
In addition, each query function allows for a user-defined predicate to be
passed. This parameter, predicate, is expected to be a callable (e.g., a
lambda expression) that receives the query object after all other query
options are applied. It is expected to return the (modified) query object.
For example:
df: pandas.DataFrame = experiments_and_runs_configurations(
predicate=lambda query: query.limit(5)
)
This would select only five entries from the database.
All results are ordered in descending order, such that the newest entries
are always first.
I.e., the limit(5) example above would automatically select the five newest
entries.
In order to avoid confusion, relation names and attributes are joined by an
underscore (_).
E.g., the ID of an environment is represented by the environment_id
attribute in the resulting data frame.
Each function expects a Session object as first argument.
I.e., the access credentials will be those that are stored in the current
runtime configuration.
If the session parameter is not supplied, a new session will be
automatically created.
However, the store API does not take care of cleaning sessions. I.e., running
more than one query function without explicitly supplying a session object will
most likely lead to dangling open connections to the database.
The best solution is to use a context manager, e.g.:
from palaestrai.store import Session
import palaestrai.store.query as palq
with Session() as session:
ers = palq.experiments_and_runs_configurations(session)
Warning
The query API is currently in beta state. That means that it is currently
caught in the impeding API changes. This includes the way the
SensorInformation, ActuatorInformation, and
RewardInformation classes are serialized.
If you encounter bugs, please report them at the
palaestrAI issue tracker
for the store subsystem.
Information about Experiments and Experiment Runs¶
- palaestrai.store.query.experiments_and_runs_configurations(session: Optional[sqlalchemy.orm.Session] = None, attrib_func: Optional[AttribPredicate] = None, predicate: Predicate = <function <lambda>>, index_col: Optional[str] = None) pd.DataFrame[source]¶
Known Experiments, Experiment Runs, Instances, and Phases.
Creates a comprehensive list containing information about
experiments
experiment runs
experiment run instances
experiment run phases.
- Parameters:
session (sqlalchemy.orm.Session, optional) – An session object created by ::palaestrai.store.Session(). If not given (
None), a new session will be automatically establishedattrib_func (Callable[[Dict[str, QueryableAttribute]], Tuple[QueryableAttribute]]) – A function that can modify each ::sqlalchemy.orm.attributes.QueryableAttribute for the select statement. This can be done by e.g. adding sqlalchemy functions when mapping from the dict to attributes. The dict thereby maps the corresponding labels to the attributes. For an example on how to get the max experiment_run_instance_id, see the Examples section.
predicate (Predicate = lambda query: query) – An additional predicate (cf. ::sqlalchemy.sql.expression) applied to the database query
index_col (Optional[str] = "experiment_run_instance_uid") – The column used as the index for the returned DataFrame
- Returns:
A dataframe containing the following columns: * experiment_id * experiment_name * experiment_document * experiment_run_id * experiment_run_uid * experiment_run_document * experiment_run_instance_id * experiment_run_instance_uid * experiment_run_phase_id * experiment_run_phase_uid * experiment_run_phase_mode
- Return type:
pandas.DataFrame
Examples
>>> from sqlalchemy import func >>> import palaestrai.store.query as palq >>> from palaestrai.store.database_model import ( ... Experiment, ... ExperimentRun, ... ) >>> experiment_run_uid = "Dummy experiment run where the agents take turns" >>> erc = palq.experiments_and_runs_configurations( ... dbh, # Session needs to be defined ... attrib_func=lambda query_attribute_dict: ( ... func.max(query_attribute) ... if query_attribute_label == "experiment_run_instance_id" ... else query_attribute ... for query_attribute_label, query_attribute in query_attribute_dict.items() ... ), ... predicate=lambda query: query.filter( ... Experiment.name ... == "Dummy Experiment record for ExperimentRun " ... + str(experiment_run_uid), ... ExperimentRun.uid == experiment_run_uid, ... ), ... )
Information about Agents and their Configurations¶
- palaestrai.store.query.agents_configurations(session: Optional[sqlalchemy.orm.Session] = None, like_dataframe: Optional[Union[pd.DataFrame, dd.DataFrame]] = None, experiment_ids: Optional[List[str]] = None, experiment_run_uids: Optional[List[str]] = None, experiment_run_instance_uids: Optional[List[str]] = None, experiment_run_phase_uids: Optional[List[str]] = None, predicate: Predicate = <function <lambda>>) pd.DataFrame[source]¶
Configurations of agents.
Creates a composite list containing information about
agents
associated experiment run phases
associated experiment run instances
associated experiment runs
associated experiments
- Parameters:
session (sqlalchemy.orm.Session, optional) – An session object created by ::palaestrai.store.Session(). If not given (
None), a new session will be automatically establishedlike_dataframe (Optional[Union[pd.DataFrame, dd.DataFrame]] = None) – Uses the given dataframe to construct a search predicate. If any of the columns
experiment_uid,experiment_run_uid, and/orexperiment_run_phase_uidare given, then the data in the frame is used in aWHERE ... IN ...-style clause. If more than one of these columns are present, they are joined byAND. Note the singular form, e.g.,experiment_uid(singular), notexperiment_run_uids(plural). The reason for this seemingly inconsistent naming is that the singular form is used in the column headers of the data frames that are returned by all query functions. Thus, thelike_dataframeparameter allows to pass a data frame from another query function (e.g., ::~experiments_and_runs_configurations) for filtering. Note that the index of the data frame is not used.experiment_ids (Optional[List[str]]) – An iterable containing experiment IDs to filter for
experiment_run_uids (Optional[List[str]]) – An iterable containing experiment run UIDs to filter for
experiment_run_instance_uids (Optional[List[str]]) – An iterable containing experiment run instance UIDs to filter for
experiment_run_phase_uids (Optional[List[str]]) – An iterable containing experiment run phase UIDs to filter for
predicate (Predicate = lambda query: query) – An additional predicate (cf. ::sqlalchemy.sql.expression) applied to the database query after all other predicates have been applied
- Returns:
A dataframe containing the following columns: * agent_id * agent_uid * agent_name * agent_configuration * experiment_run_phase_id * experiment_run_phase_uid * experiment_run_phase_configuration * experiment_run_phase_configuration * experiment_run_instance_uid * experiment_run_id * experiment_run_uid * experiment_id * experiment_name
- Return type:
pandas.DataFrame
Information about Environments and their Configurations¶
- palaestrai.store.query.environments_configurations(session: Optional[sqlalchemy.orm.Session] = None, like_dataframe: Optional[Union[pd.DataFrame, dd.DataFrame]] = None, experiment_uids: Optional[List[str]] = None, experiment_run_uids: Optional[List[str]] = None, experiment_run_phase_uids: Optional[List[str]] = None, predicate: Predicate = <function <lambda>>) pd.DataFrame[source]¶
Configurations of Environments.
Creates a composite list containing information about
agents
associated experiment run phases
associated experiment run instances
associated experiment runs
associated experiments
- Parameters:
session (sqlalchemy.orm.Session, optional) – An session object created by ::palaestrai.store.Session(). If not given (
None), a new session will be automatically establishedlike_dataframe (Optional[Union[pd.DataFrame, dd.DataFrame]] = None) – Uses the given dataframe to construct a search predicate. Refer to the parameter documentation of ::~experiments_and_runs_configurations
experiment_uids (Optional[List[str]]) – An iterable containing experiment UIDs to filter for
experiment_run_uids (Optional[List[str]]) – An iterable containing experiment run UIDs to filter for
experiment_run_phase_uids (Optional[List[str]]) – An iterable containing experiment run phase UIDs to filter for
predicate (Predicate = lambda query: query) – An additional predicate (cf. ::sqlalchemy.sql.expression) applied to the database query after all other predicates have been applied
- Returns:
A dataframe containing the following columns: * environment_id * environment_uid * environment_type * environment_parameters * experiment_run_phase_id * experiment_run_phase_uid * experiment_run_phase_configuration * experiment_run_phase_configuration * experiment_run_instance_uid * experiment_run_id * experiment_run_uid * experiment_id * experiment_name
- Return type:
pandas.DataFrame
Cumulative Rewards/Objective Values¶
- palaestrai.store.query.muscles_cumulative_objective(session: Optional[sqlalchemy.orm.Session] = None, like_dataframe: Optional[Union[pd.DataFrame, dd.DataFrame]] = None, experiment_ids: Optional[List[str]] = None, experiment_run_uids: Optional[List[str]] = None, experiment_run_instance_uids: Optional[List[str]] = None, experiment_run_phase_uids: Optional[List[str]] = None, experiment_run_phase_numbers: Optional[List[int]] = None, modes: Optional[List[str]] = None, muscle_action_episodes: Optional[List[int]] = None, agent_names: Optional[List[str]] = None, predicate: Predicate = <function <lambda>>) pd.DataFrame[source]¶
Cumulative object values of rollout workers (i.e., per-worker rewards)
The resulting dataframe lists the cumulative reward of each worker of agents in phases of the experiment. Results can be filtered by providing the respective parameters, e.g., to get the cumulative objective values of agents in one particular phase, use the
experiment_run_phase_uidsparameter. Thelike_dataframewill probably be the most convenient method for filtering. Supplying both a dataframe vialike_dataframeand any other filter parameter filters according to both.- Parameters:
session (sqlalchemy.orm.Session, optional) – An session object created by ::palaestrai.store.Session(). If not given (
None), a new session will be automatically establishedlike_dataframe (Optional[Union[pd.DataFrame, dd.DataFrame]] = None) – Uses the given dataframe to construct a search predicate. Refer to the parameter documentation of ::~experiments_and_runs_configurations
experiment_ids (Optional[List[str]]) – An iterable containing experiment IDs to filter for
experiment_run_uids (Optional[List[str]]) – An iterable containing experiment run UIDs to filter for
experiment_run_instance_uids (Optional[List[str]]) – An iterable containing experiment run instance UIDs to filter for
experiment_run_phase_uids (Optional[List[str]]) – An iterable containing experiment run phase UIDs to filter for
experiment_run_phase_numbers (Optional[List[int]]) – An iterable containing experiment run phase numbers to filter for
modes (Optional[List[str]]) – An iterable containing modes to filter for
muscle_action_episodes (Optional[List[int]]) – An iterable containing muscle action episodes to filter for
agent_names (Optional[List[str]] = None) – An iterable containing agent UIDs to filter for
predicate (Predicate = lambda query: query) – An additional predicate (cf. ::sqlalchemy.sql.expression) applied to the database query after all other predicates have been applied
- Returns:
The dataframe contains the following columns: * agent_id * agent_uid * agent_name * rollout_worker_uid * muscle_cumulative_objective * experiment_run_phase_id * experiment_run_phase_uid * experiment_run_phase_configuration * experiment_run_instance_uid * experiment_run_id * experiment_run_uid * experiment_id * experiment_name
- Return type:
pd.DataFrame
Muscle Action Details¶
- palaestrai.store.query.muscle_actions(session: Optional[sqlalchemy.orm.Session] = None, like_dataframe: Optional[Union[pd.DataFrame, dd.DataFrame]] = None, experiment_ids: Optional[List[str]] = None, experiment_run_uids: Optional[List[str]] = None, experiment_run_instance_uids: Optional[List[str]] = None, experiment_run_phase_uids: Optional[List[str]] = None, modes: Optional[List[str]] = None, episodes: Optional[List[int]] = None, agent_names: Optional[List[str]] = None, predicate: Predicate = <function <lambda>>) pd.DataFrame | dd.DataFrame[source]¶
All action data of a ::~.Muscle: readings, setpoints, and rewards
The resulting dataframe contains information about:
muscle sensor readings
muscle actuator setpoints
muscle rewards
experiment run phases
experiment run instances
experiment runs
experiments
- Parameters:
session (sqlalchemy.orm.Session, optional) – An session object created by ::palaestrai.store.Session(). If not given (
None), a new session will be automatically establishedlike_dataframe (Optional[Union[pd.DataFrame, dd.DataFrame]] = None) – Uses the given dataframe to construct a search predicate. Refer to the parameter documentation of ::~experiments_and_runs_configurations
experiment_ids (Optional[List[str]]) – An iterable containing experiment IDs to filter for
experiment_run_uids (Optional[List[str]]) – An iterable containing experiment run UIDs to filter for
experiment_run_instance_uids (Optional[List[str]]) – An iterable containing experiment run instance UIDs to filter for
experiment_run_phase_uids (Optional[List[str]]) – An iterable containing experiment run phase UIDs to filter for
modes (Optional[List[str]] = None) – An iterable containing MuscleAction modes to filter for
episodes (Optional[List[int]] = None) – An iterable containing MuscleAction episodes to filter for
agent_names (Optional[List[str]] = None) – An iterable containing agent names to filter for
predicate (Predicate = lambda query: query) – An additional predicate (cf. ::sqlalchemy.sql.expression) applied to the database query after all other predicates have been applied
- Returns:
This method returns a dask dataframe by default, unless the predicate adds a
LIMITorOFFSETclause. The dataframe contains the following columns: * muscle_action_id * muscle_action_walltime * muscle_action_simtimes * muscle_sensor_readings * muscle_actuator_setpoints * muscle_action_rewards * muscle_action_objective * mode * episode * agent_id * agent_uid * agent_name * rollout_worker_uid * experiment_run_phase_id * experiment_run_phase_uid * experiment_run_phase_configuration * experiment_run_instance_uid * experiment_run_id * experiment_run_uid * experiment_id * experiment_name- Return type:
Union[pd.DataFrame, dd.DataFrame]
Low-Level Access¶
When the query API is not sufficient, the database can be accessed using the ORM classes in ::palaestrai.store.database_model. An example would be:
import palaestrai.core
import palaestrai.store.database_model as dbm
import sqlalchemy.orm
import json
# pandapower is used by midas environments, this might differ by usecase
import pandapower as pp
from pandapower.plotting import simple_plot
# Create an alchemy engine
alchemyEngine= create_engine('postgresql+psycopg2://postgres:passwordforpalaestrai@127.0.0.1:5432/Palaestrai', pool_recycle=3600);
# Create a session
session_maker = sqlalchemy.orm.sessionmaker()
session_maker.configure(bind=alchemyEngine)
dbSession = session_maker()
# Query experiments
query= dbSession.query(dbm.Experiment)
# Get the last experiment
exps = query.order_by(dbm.Experiment.id.desc())
exp = exps[1]
# Get all runs
runs = exp.experiment_runs
run = runs[0]
# Get all simulation runs
sims = run.simulation_instances
sim = sims[0]
# Get all muscles
muscles = sim.muscles
muscle1 = muscles[0]
muscle2 = muscles[1]
# Get all muscle actions
m1_actions = muscle1.muscle_actions
# Get rewards from the muscle actions
rewards = [a.reward for a in muscle1.muscle_actions]
# Get environment conductors
ecs = sim.environment_conductors
# Get first ec
ec = ecs[0]
# Get world states
world_states = ec.world_states
# get the last 10 states but not the last one because its empty
states = world_states[-10:-1]
# for every state load the json
# extract the external grid state
# load the panda power net
# extract the values and store it
external_grids = None
for state in states:
world_state_json = json.loads(state.state_dump)
s = [x for x in world_state_json if x["sensor_id"] == "Powergrid-0.Grid-0.grid_json"]
net = pp.from_json_string(s[0]['sensor_value'])
if external_grids is None:
external_grids = net.res_ext_grid
else:
external_grids = external_grids.append(net.res_ext_grid)
# Since the data are present in their original form,
# all functions from the pandapower framework are applicable for data analysis,
# for example build-in plotting functions:
simple_plot(net)
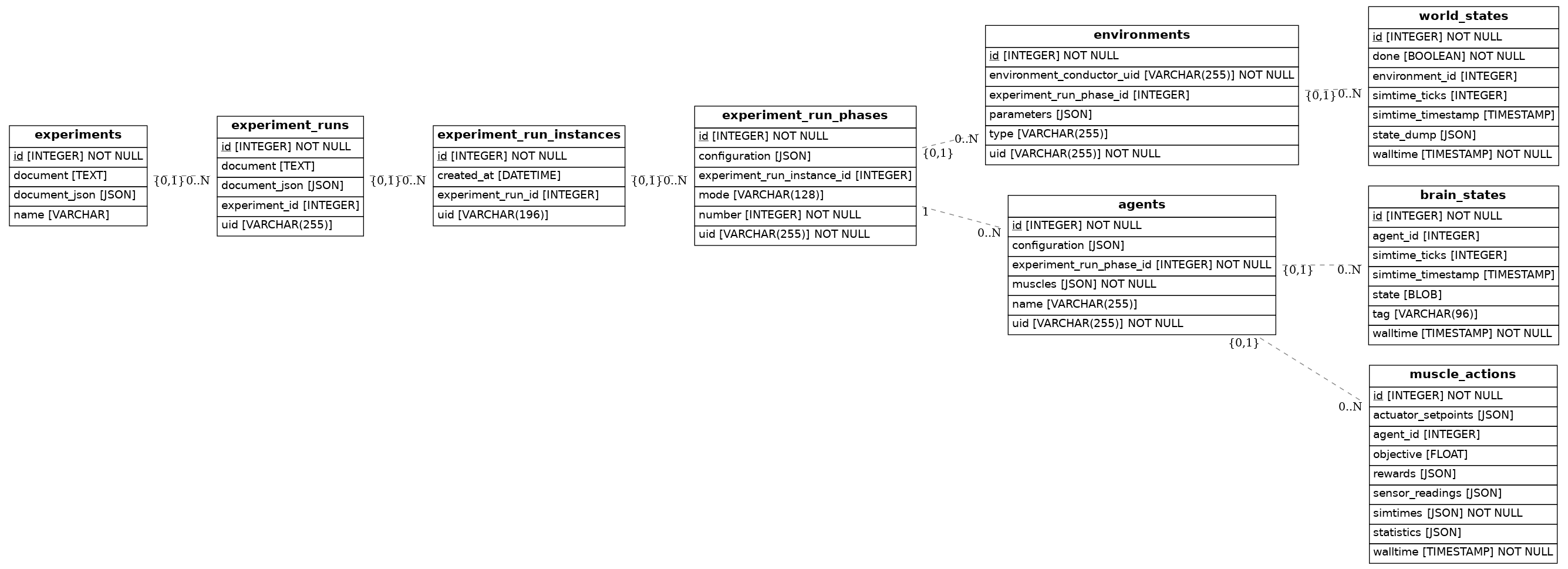
To get a full overview of what can be done with the databse model visit The SQLAlchemy Documentation. An overview of the data-structure can be found below.